
DevOps to MLOps
The Essential Tools and Concepts You Must Master

MLOps is not “data science with YAML” — it’s distributed systems, reliability, and cost control for models.
Below is a clean mental map of what actually matters when a DevOps → MLOps transition is done correctly.
Core Concept Shift (Most Important)
DevOps mindset
Deploy services reliably
MLOps mindset
Deploy uncertainty reliably
Models:
Change behavior without code changes
Degrade silently
Cost money per inference
Depend on data quality, not just uptime
If you internalize this, everything else clicks.
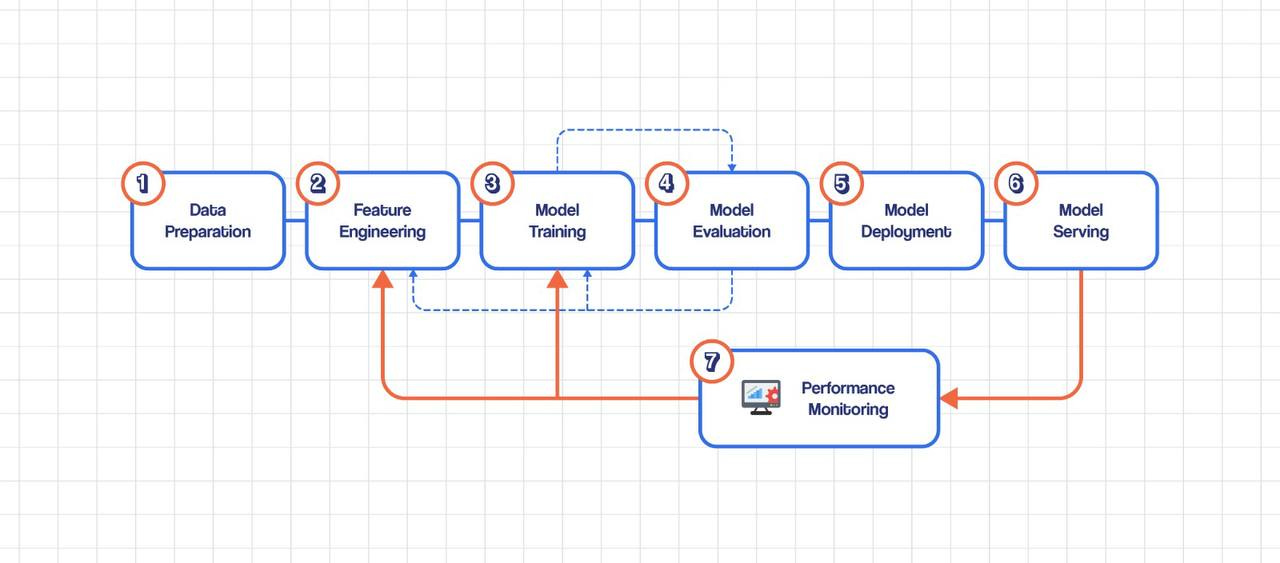
2️⃣ Model Lifecycle (You must own this end-to-end)

You should be comfortable with:
Data ingestion
Feature engineering
Training
Validation
Packaging
Serving
Monitoring
Retraining
DevOps engineers usually jump straight to serving.
Strong MLOps engineers control the full loop.
Data Fundamentals (Non-Negotiable)
You don’t need to be a data scientist, but you must understand:
Concepts
Training vs validation vs test sets
Batch vs streaming data
Data leakage (silent model killer)
Feature skew (train ≠ inference data)
Dataset versioning
Tools
S3
→ Acts as the source of truth for raw, processed, and training dataDelta Lake / Iceberg / Hudi
→ Enables reproducible datasets with versioning, schema evolution, and time travelKafka
→ Powers real-time data streams and online feature generationAirflow / Dagster / Prefect
→ Orchestrates data pipelines, model training, and retraining workflows
💡 If you understand Airflow + data contracts, you’re already ahead.
Feature Stores (The Missing Layer)
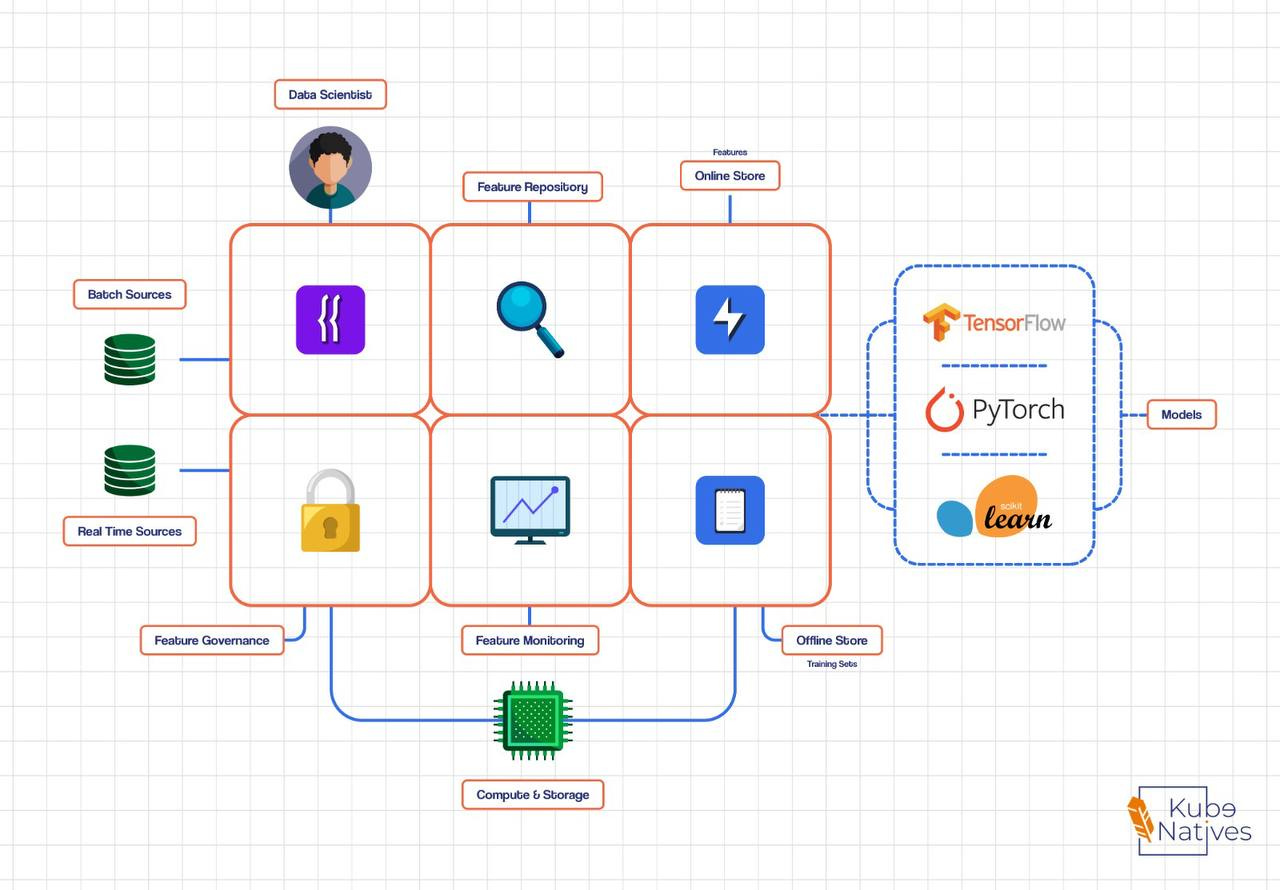
Why feature stores exist
Prevent training/serving skew
Reuse features across teams
Enable low-latency inference
Tools
Feast (industry standard)
Tecton (enterprise)
Vertex AI Feature Store
👉 Think of a feature store as:
A ConfigMap for models, but with time awareness
Training Infrastructure
What changes from DevOps
Training is ephemeral
Failures are expected
Cost is the main enemy
Key concepts
Distributed training
Spot/preemptible instances
Checkpointing
GPU scheduling & bin packing
Tools
Kubernetes
→ Serves as the control plane for training and inference workloadsKubeflow / Argo Workflows
→ Orchestrates model training pipelines and ML workflowsRay
→ Enables distributed machine learning and parallel model trainingSpark
→ Handles large-scale feature processing and data transformationsNVIDIA Operator
→ Manages the GPU lifecycle, drivers, and device plugins on Kubernetes
💡 GPU utilization matters more than CPU ever did.
6️⃣ Model Packaging & Registry
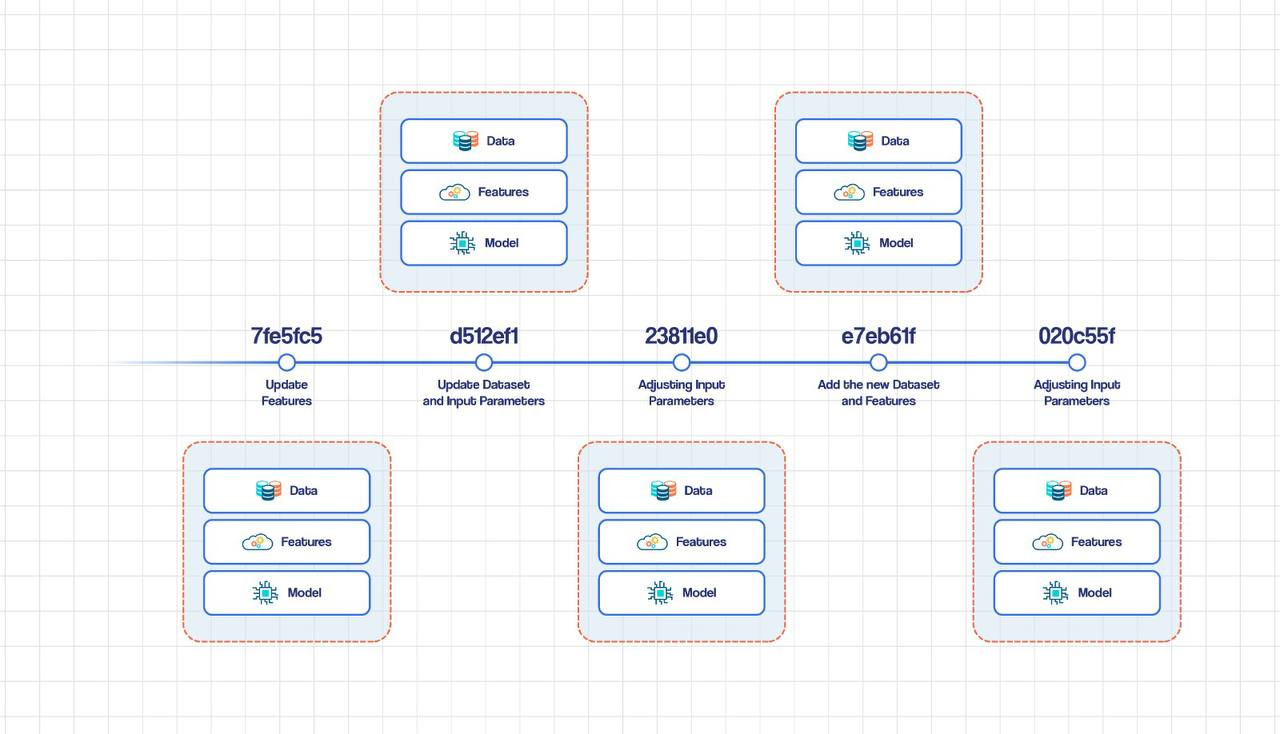
Must-know ideas
Model ≠ code
Model version ≠ data version
Rollback must be instant
Tools
MLflow (mandatory knowledge)
Weights & Biases
Hugging Face Hub (LLMs)
Think of MLflow as:
Docker Registry + Git + Metrics for models
Model Serving (This is where DevOps shines)
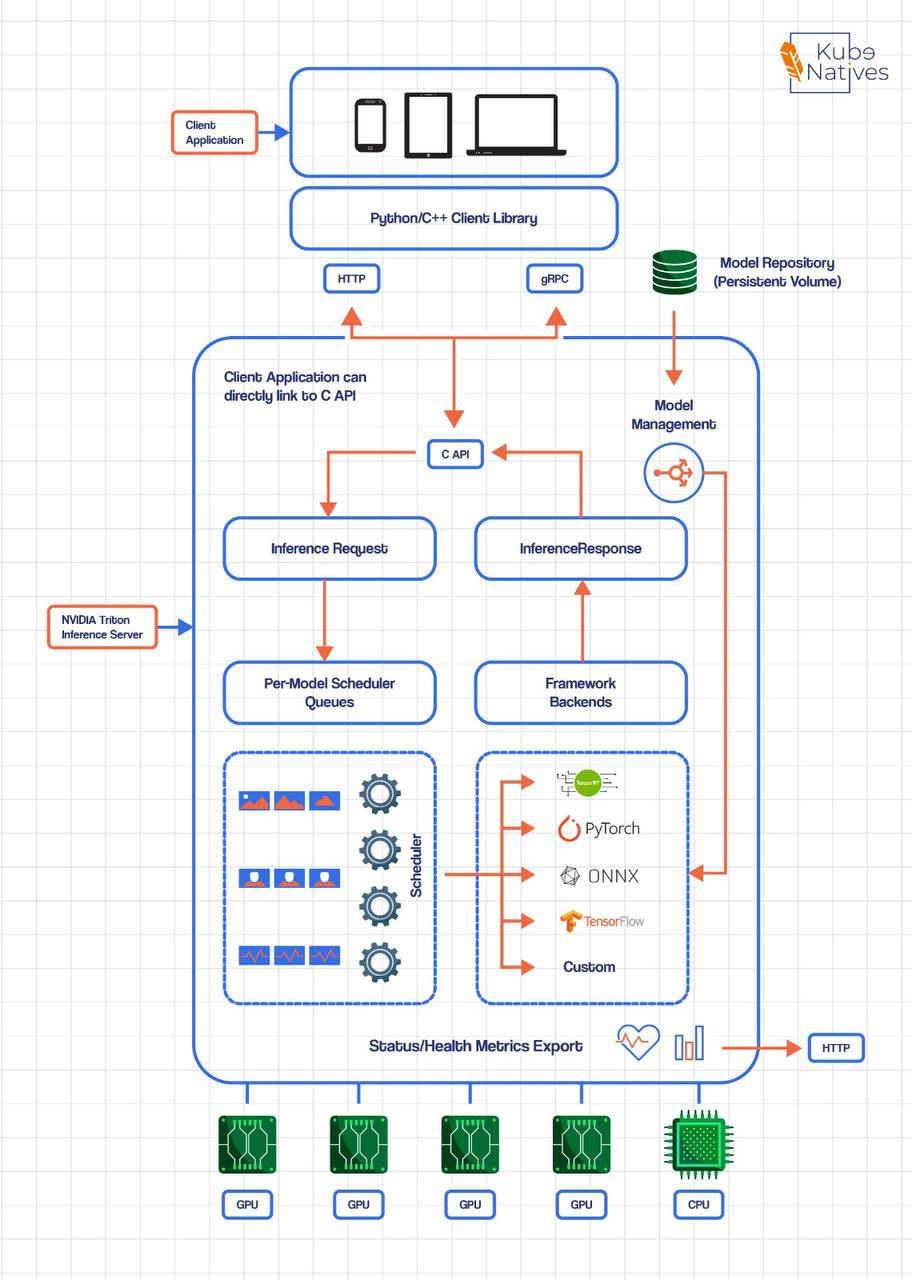
Serving patterns
Batch inference
Online REST/gRPC
Streaming inference
Async inference queues
Tools
KServe
→ Used for general ML model serving on KubernetesTriton Inference Server
→ Optimized for high-performance GPU inferencevLLM
→ Designed specifically for LLM inference with efficient memory usageBentoML
→ Enables fast model productization and API packagingFastAPI
→ Ideal for custom model serving and bespoke inference logic
👉 This is where your Kubernetes + ingress skills dominate.
Observability for Models (Different from apps)
What to monitor
Prediction distribution drift
Feature drift
Model accuracy decay
Latency per token (LLMs)
Cost per request
Tools
Evidently AI
WhyLabs
Prometheus + custom metrics
OpenTelemetry (for inference traces)
Models can be “up” and still be useless.
CI/CD for ML (Not GitOps alone)
Differences from DevOps CI/CD
Pipelines trigger on data
Artifacts are models
Rollouts depend on metrics
Patterns
Shadow deployments
Canary inference
A/B testing
Human-in-the-loop approvals
Tools
GitHub Actions / GitLab CI
Argo CD (for serving)
Kubeflow Pipelines (training)
Feature flags for models
Cost Engineering (Your secret weapon)
This is where most ML teams fail.
You should understand:
GPU time vs batch size
Token-based pricing
Model quantization
Caching embeddings
Autoscaling pitfalls for GPUs
💡 An MLOps engineer who saves GPU cost is more valuable than one who trains a better model.
Learning Order (Practical Path)
Since you already have strong infra skills, I’d suggest:
MLflow + experiment tracking
Feature stores (Feast)
Model serving (vLLM / Triton)
Drift monitoring
Cost optimization for GPUs
Full lifecycle automation
Final Reality Check
MLOps is DevOps + Data + Statistics + Cost Engineering
You don’t need to become a data scientist.
You need to become the person who makes models reliable, cheap, and trustworthy.