
How Kubernetes Uses etcd: The Cluster's Source of Truth
Raft consensus, optimistic locking, and why your 3 AM pages start here

Every Pod, Service, and Deployment you create needs to live somewhere permanently. That’s etcd’s job.
It’s Kubernetes’s single source of truth - a distributed key-value store that holds your entire cluster state.
The Architecture Rule You Need to Know
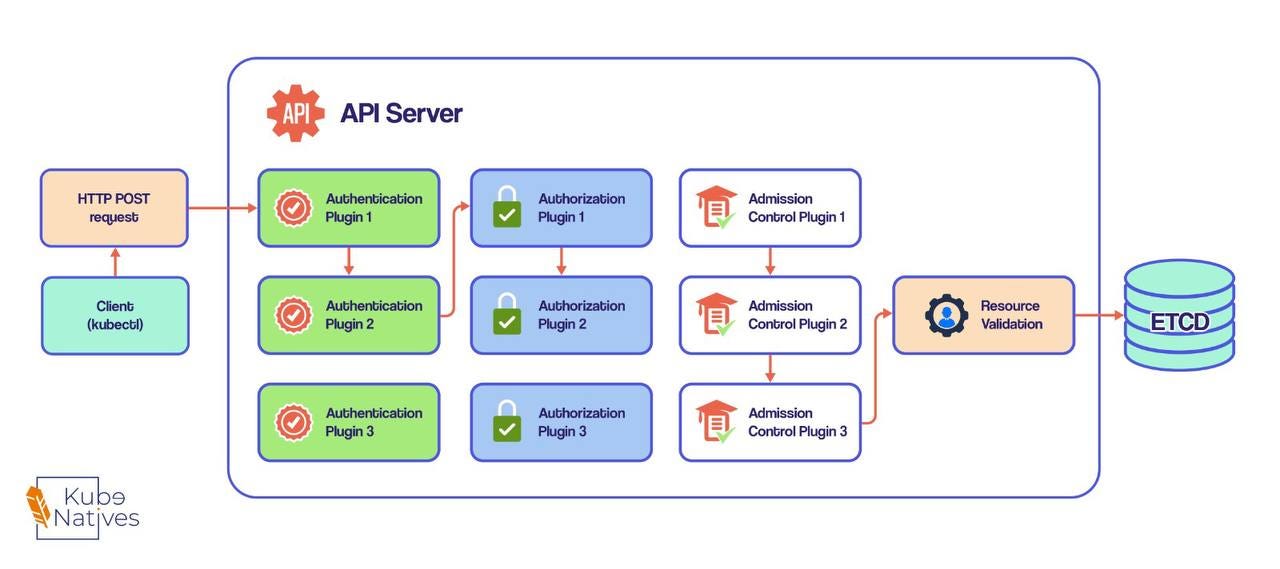
Only the API server communicates directly with etcd. Everything else goes through the API server first.
This isn’t just good design - it’s critical for two reasons:
Single validation point: One place to enforce rules and prevent bad data
Easy to swap: Want to replace etcd someday? Only one component needs changes
Understanding Optimistic Locking (Without the Academic Jargon)
Here’s the problem: What happens when two engineers try to update the same Deployment simultaneously?
etcd uses optimistic locking - think of it like document version numbers. Every resource has a metadata.resourceVersion field. When you update something:
You read the resource (version = 42)
You modify it locally
You send it back with version 42
If someone else updated it first (now version 43), your update gets rejected
You re-read and try again
First write wins. Second write retries.
This prevents the classic “last write wins” problem that corrupts data.
How Your Resources Actually Live in etcd
Think of etcd like a filesystem. Everything lives under /registry:
/registry/
├── pods/
│ ├── default/
│ │ ├── nginx-pod-abc123
│ │ └── api-pod-xyz789
│ └── kube-system/
├── deployments/
├── services/
└── secrets/ (encrypted since K8s 1.7)
Each entry? Just the full JSON manifest of that resource. Simple.
Production Reality: Why Run Multiple etcd Instances?
Here’s where it gets interesting. For HA, you run 3, 5, or 7 etcd instances. But why odd numbers?
The Math That Matters:
1 instance: Can’t fail (0 failures tolerated)
2 instances: Need both for majority = worse than 1 (0 failures tolerated)
3 instances: Need 2 for majority = 1 failure tolerated ✓
4 instances: Need 3 for majority = 1 failure tolerated (same as 3, but higher failure chance)
5 instances: Need 3 for majority = 2 failures tolerated ✓
7 instances: Need 4 for majority = 3 failures tolerated ✓
Why 2 or 4 instances makes no sense: You need a majority (>50%) to make decisions. With 2 instances, if one fails, you have 50% - not enough.
With 4 instances, if one fails, you need all 3 remaining for majority. That’s the same fault tolerance as 3 instances, but with higher probability of cascading failures.
The RAFT Algorithm in Plain English
etcd uses RAFT consensus to keep instances in sync. The key insight: at any moment, each node either has:
The current agreed-upon state, OR
A previous agreed-upon state
Never a divergent, made-up state.
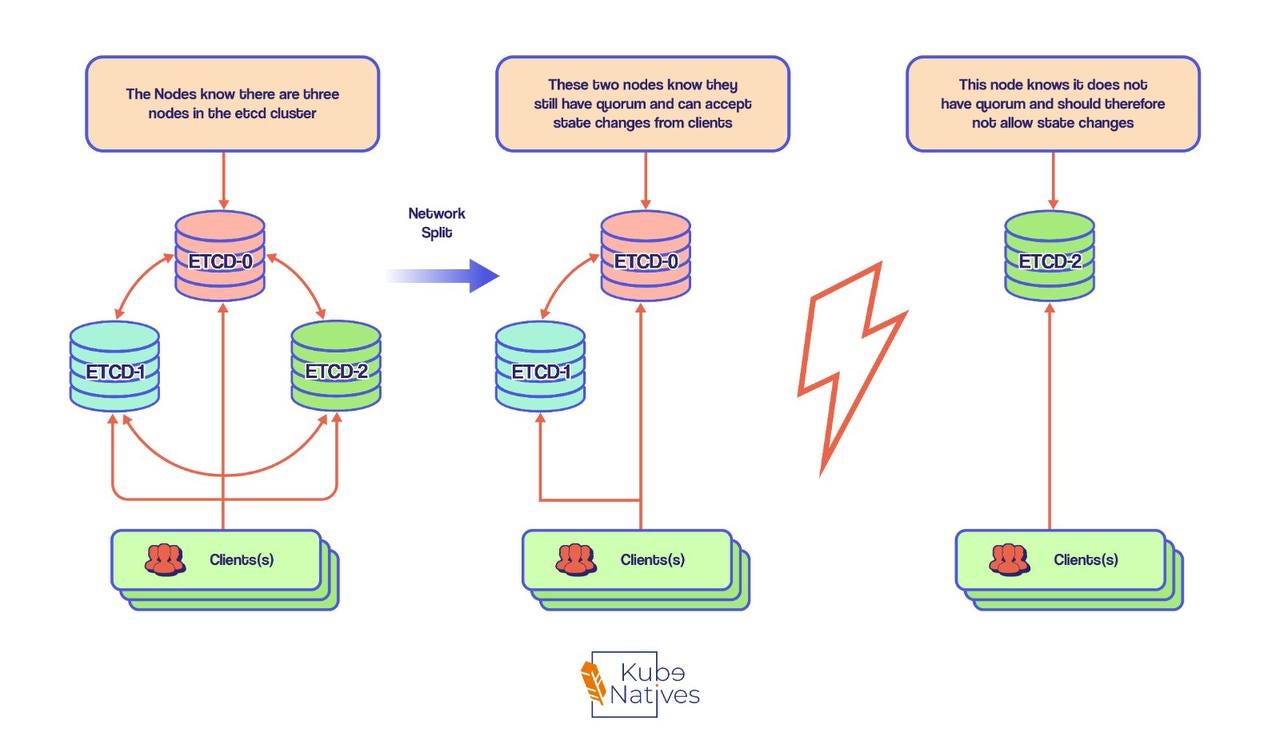
During a network split, only the partition with majority (>50% nodes) can accept writes. The minority partition becomes read-only with stale data. When the network heals, minority catches up.
For Your Production Cluster:
Small cluster (<50 nodes): 3 etcd instances is fine
Large cluster: 5 instances handles most failures
Massive cluster: 7 instances maximum (diminishing returns after this)
More instances ≠ better. Each additional instance adds coordination overhead.
The One Debug Command You Actually Need
# Check etcd health
etcdctl endpoint health --cluster
# See what's stored (etcd v3)
etcdctl get /registry --prefix --keys-only
Key Takeaway: etcd is the stateful foundation of your stateless orchestrator. Understand its storage model and consensus requirements, and you’ll debug cluster issues 10x faster.