
3-Node HA Setup: Quorum, Split-Brain, and Why the Math Matters
The number 3 is not arbitrary. It is the minimum that makes distributed consensus work.

Every production Kubernetes guide tells you to run 3 control plane nodes. Most never explain why.
It is not about redundancy. You could have redundancy with 2 nodes. It is about quorum. And quorum is the reason your cluster stays consistent when things fail.
This article explains why 3, what happens with 2, 4, and 5, and the exact failure scenarios you need to plan for.
The Quorum Formula
etcd uses the Raft consensus algorithm. Every write must be acknowledged by a majority of members before it is committed.
The formula:
Quorum = (N / 2) + 1
3 nodes → quorum = 2 → tolerates 1 failure
5 nodes → quorum = 3 → tolerates 2 failures
7 nodes → quorum = 4 → tolerates 3 failures
The general rule: a cluster of N nodes can tolerate (N - 1) / 2 failures.
This is why 3 is the minimum for HA. With 3 nodes and a quorum of 2, you can lose 1 node and the cluster keeps accepting writes. With 2 nodes, the quorum is also 2. Lose 1 and you lose quorum. The cluster goes read only.
2 nodes is worse than 1 node for write availability. With 1 node, there is no consensus requirement. Writes always succeed (until that node dies). With 2 nodes, both must be healthy for writes to succeed. You added hardware but reduced availability.
What Happens When You Lose Quorum
When etcd loses quorum, it enters a read only state. The API server can still read existing state (pods, services, configurations). But it cannot write.
This means:
No new pods can be created. No existing pods can be modified. No Deployments can be scaled. No ConfigMaps can be updated. No new nodes can join. No Secrets can be created or rotated.
Existing workloads continue running. The kubelet on each node keeps running its containers. Health checks continue. But nothing can change.
If a running pod crashes during a quorum loss, it will not be restarted by a controller because the controller cannot write the new pod spec to etcd. The kubelet will try to restart the container locally based on the restartPolicy, but the Deployment controller cannot create a replacement.
This is why quorum loss is a critical incident. The cluster looks alive but is frozen.
Why 3, Not 4
4 nodes seems like an improvement over 3. More hardware, more redundancy. But the math tells a different story.
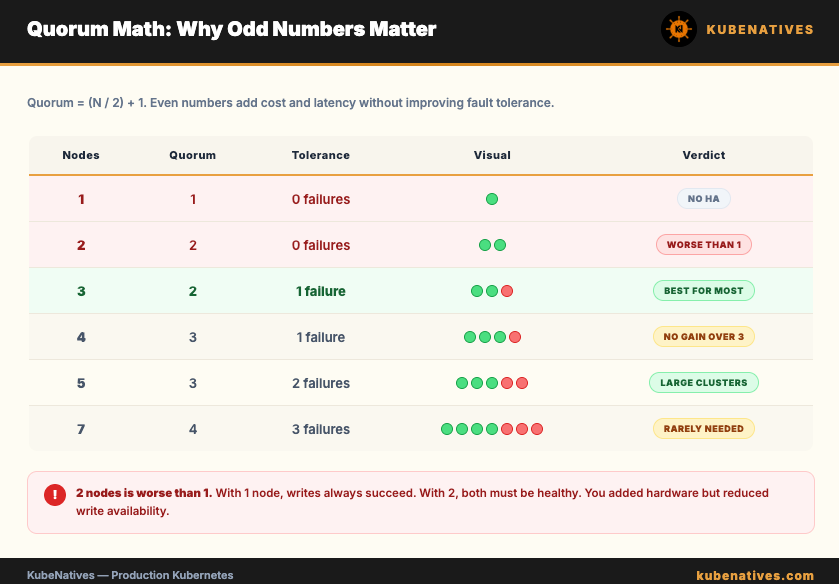
4 nodes tolerates the same number of failures as 3. You added a node but gained zero additional fault tolerance. You did add more write latency though, because every write now needs 3 acknowledgments instead of 2.
This is why production clusters use odd numbers: 3, 5, or 7. Even numbers add cost and latency without improving fault tolerance.
When 5 makes sense. If losing a single node keeps you up at night because maintenance windows overlap with failures, go to 5. A 5 node cluster tolerates 2 simultaneous failures. This means you can take 1 node down for maintenance and still survive an unexpected failure.
For most production clusters under 500 nodes, 3 is the right answer. The cost and operational complexity of 5 etcd nodes is only justified when the blast radius of quorum loss is extremely high.
Split-Brain: The Scenario Everyone Fears

Split-brain happens when a network partition divides the cluster into two groups, and both groups think they are the active cluster.
In traditional systems without consensus, this is catastrophic. Both sides accept writes. When the partition heals, you have conflicting state and no way to automatically reconcile.
Raft prevents this by design. Here is what actually happens with 3 nodes:
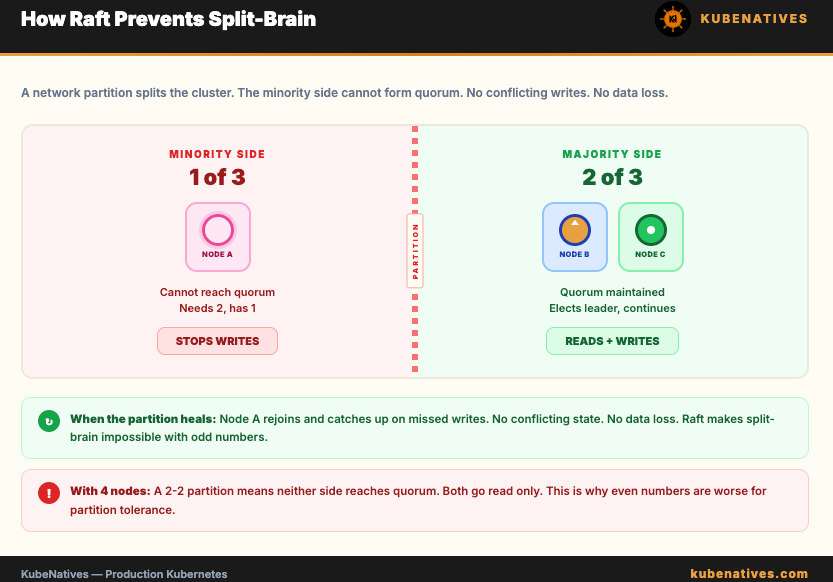
Scenario: Network partition isolates Node A from Nodes B and C.
Node A is alone. It has 1 out of 3 members. It cannot form a quorum (needs 2). It stops accepting writes. It becomes read-only.
Nodes B and C have 2 out of 3 members. They form a quorum. They elect a new leader (if A was the leader). Writing continues normally.
When the partition heals, Node A rejoins and catches up on all the writes it missed. No conflicting state. No data loss.
The key insight: Raft makes split-brain impossible as long as you have an odd number of nodes. The minority side always fails to reach a quorum. The majority side always succeeds. There is never ambiguity about which side is authoritative.
With an even number (4 nodes), a network partition could create a 2-2 split. Neither side has a quorum. Both sides go read-only. This is another reason odd numbers are better.
The 3 Node Architecture
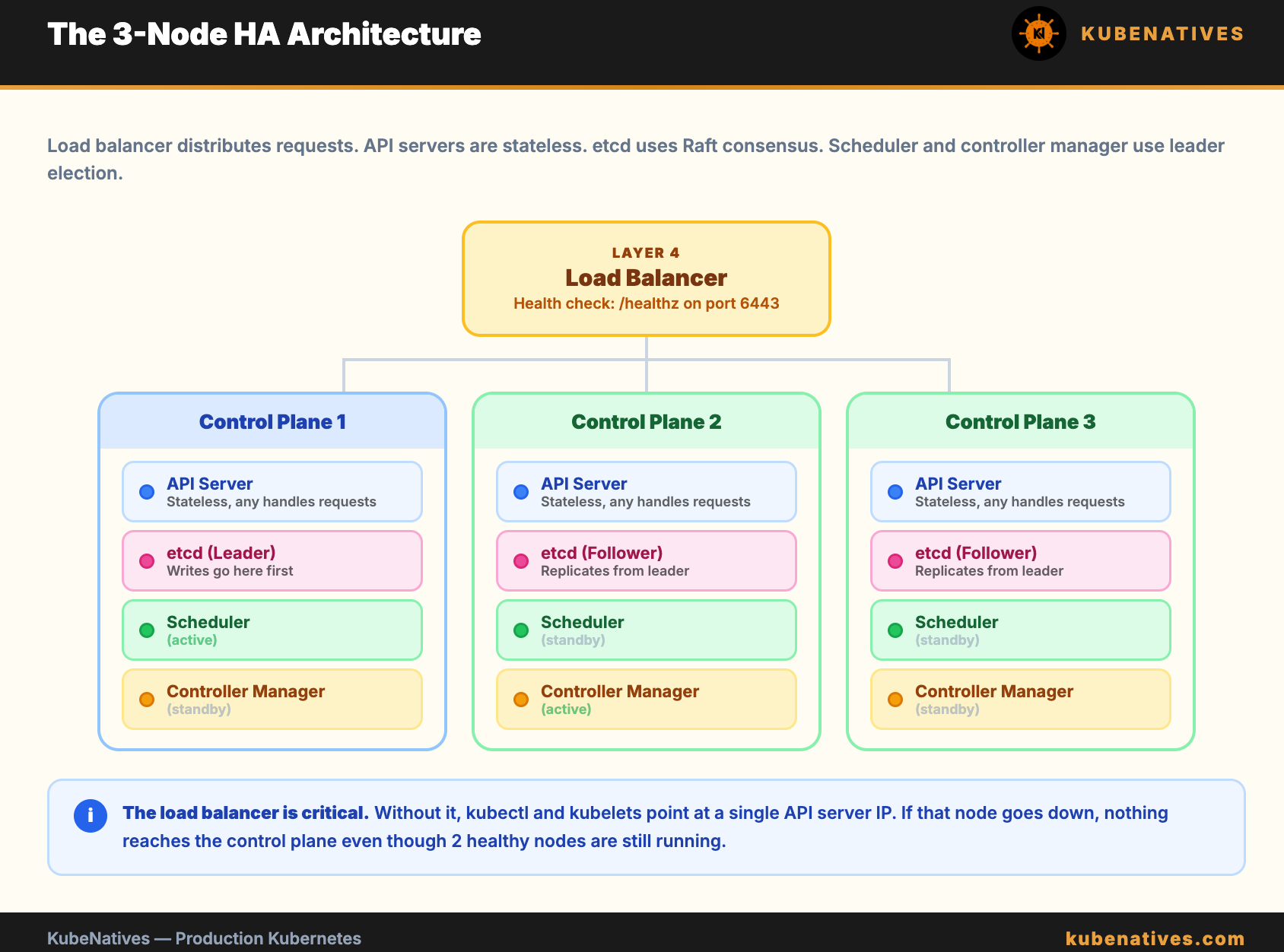
The load balancer distributes API requests across all 3 API servers. The API servers are stateless. Anyone can handle any request.
etcd runs on all 3 nodes (stacked topology). One etcd member is the leader. Writes go to the leader and are replicated to followers.
The scheduler and controller manager use leader election. Only one instance is active at a time. If the active instance dies, another takes over within seconds.
The load balancer is critical. Without it, kubectl and the kubelets point at a single API server IP. If that node goes down, nothing can reach the control plane even though 2 healthy nodes are still running.
Use a Layer 4 (TCP) load balancer. Do not use Layer 7 (HTTP). The API server handles its own TLS. Health check endpoint: /healthz on port 6443.
Stacked vs External in HA Context
In the architecture above, etcd runs on the same nodes as the API server. This is stacked topology.
External topology separates etcd onto its own dedicated nodes:

External topology means 6 nodes instead of 3. More cost. More complexity. But etcd gets a dedicated disk and CPU. No resource contention with the API server.
Which one for HA? Both provide quorum protection. The difference is performance under load, not availability.
Stacked is fine for clusters with fewer than 200 nodes. Simple to set up. Kubeadm supports it natively.
External becomes necessary when etcd disk latency degrades because the API server is consuming the same I/O bandwidth. We covered this in detail in the Stacked vs External etcd article.
Failure Scenarios: What Actually Happens
Scenario 1: One node goes down (expected)
Quorum is maintained (2 of 3). A new etcd leader is elected if the failed node was the leader. The scheduler and controller manager fail over if they were active on the failed node. API requests continue through the load balancer to the remaining 2 nodes.
Impact: Brief spike in API latency during leader election (typically under 5 seconds). No service disruption.
Scenario 2: Two nodes go down simultaneously
Quorum is lost (1 of 3). etcd becomes read only. The API server can read state but cannot write. No new pods, deployments, or changes.
Existing workloads keep running. The kubelet on worker nodes continues managing its containers. But nothing can be updated or replaced.
Recovery: Bring at least 1 node back online to restore quorum. etcd will automatically re-form consensus.
Scenario 3: etcd data corruption on one node
The corrupted member falls behind. etcd detects the inconsistency through Raft log verification. The member stops participating in consensus.
Recovery: Remove the corrupted member from the cluster. Provision a new node. Add it as a new etcd member. It will automatically replicate data from the healthy members.
# Remove the bad member
etcdctl member remove MEMBER_ID
# Add a new member
etcdctl member add new-node --peer-urls=https://NEW_IP:2380
# Start etcd on the new node with the --initial-cluster-state=existing flag
Scenario 4: Disk fills up on one node
etcd performance degrades as the disk fills. Write latency increases. If the etcd database hits its storage quota, that member triggers a NOSPACE alarm.
If only one member hits NOSPACE, the cluster continues (2 of 3 are healthy). But you should act immediately because the remaining members are likely on the same trajectory.
Recovery: Follow the NOSPACE runbook (compact, defrag, disarm alarm). Then investigate why disk usage grew and fix the root cause.
Scenario 5: Control plane node scheduled for maintenance
Drain the node’s workloads (if it also runs worker pods). The other 2 nodes maintain quorum. Perform maintenance. Bring the node back.
Important: Never take 2 nodes down for maintenance simultaneously. With 3 nodes, losing 2 means quorum loss. Always verify the first node is healthy and has rejoined the etcd cluster before starting maintenance on the second.
# Verify cluster health before maintenance
etcdctl endpoint health --cluster
etcdctl endpoint status --write-out=table
The Health Checks You Need
Daily automated check
#!/bin/bash
# etcd-health-check.sh
CERTS="--cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key"
echo "=== Cluster Health ==="
ETCDCTL_API=3 etcdctl endpoint health --cluster $CERTS
echo ""
echo "=== Member Status ==="
ETCDCTL_API=3 etcdctl endpoint status --cluster --write-out=table $CERTS
echo ""
echo "=== Active Alarms ==="
ETCDCTL_API=3 etcdctl alarm list $CERTS
Prometheus alerts for quorum
groups:
- name: etcd-quorum
rules:
- alert: EtcdMemberDown
expr: up{job="etcd"} == 0
for: 2m
labels:
severity: critical
annotations:
summary: "etcd member {{ $labels.instance }} is down"
description: "With 3 members, losing 1 means you are one failure from quorum loss."
- alert: EtcdInsufficientMembers
expr: count(up{job="etcd"} == 1) < 2
for: 1m
labels:
severity: page
annotations:
summary: "etcd cluster has lost quorum"
description: "Fewer than 2 etcd members are healthy. Cluster is read-only."
The Bottom Line
The number 3 is not arbitrary. It is the minimum required for distributed consensus to work with fault tolerance.
3 nodes, quorum of 2, tolerates 1 failure. Add a load balancer in front. Use odd numbers. Never take 2 nodes down at the same time.
If you understand quorum, you understand why your cluster survives node failures. If you do not, you will learn the hard way at 3 AM.
Next week: Why Your GPU Pods Are Pending: Debugging Kubernetes GPU Scheduling.
If you are running production Kubernetes clusters, I cover control plane internals, GPU infrastructure, and model serving every week. Subscribe at kubenatives.com.