
LLMs: What DevOps Engineers Actually Need to Know
Everyone is talking about LLMs. Few understand how they work. Even fewer know how to run them in production.


LLM ≠ Magic
LLM stands for Large Language Model — a deep neural network trained to predict the next word in a sentence. It’s not AI magic. It's a statistical engine backed by massive infrastructure.
If you’re a DevOps engineer, you don’t need to know the math.
But you do need to know the stack.
🧱 The LLM Infrastructure Stack (Kubernetes-Friendly)
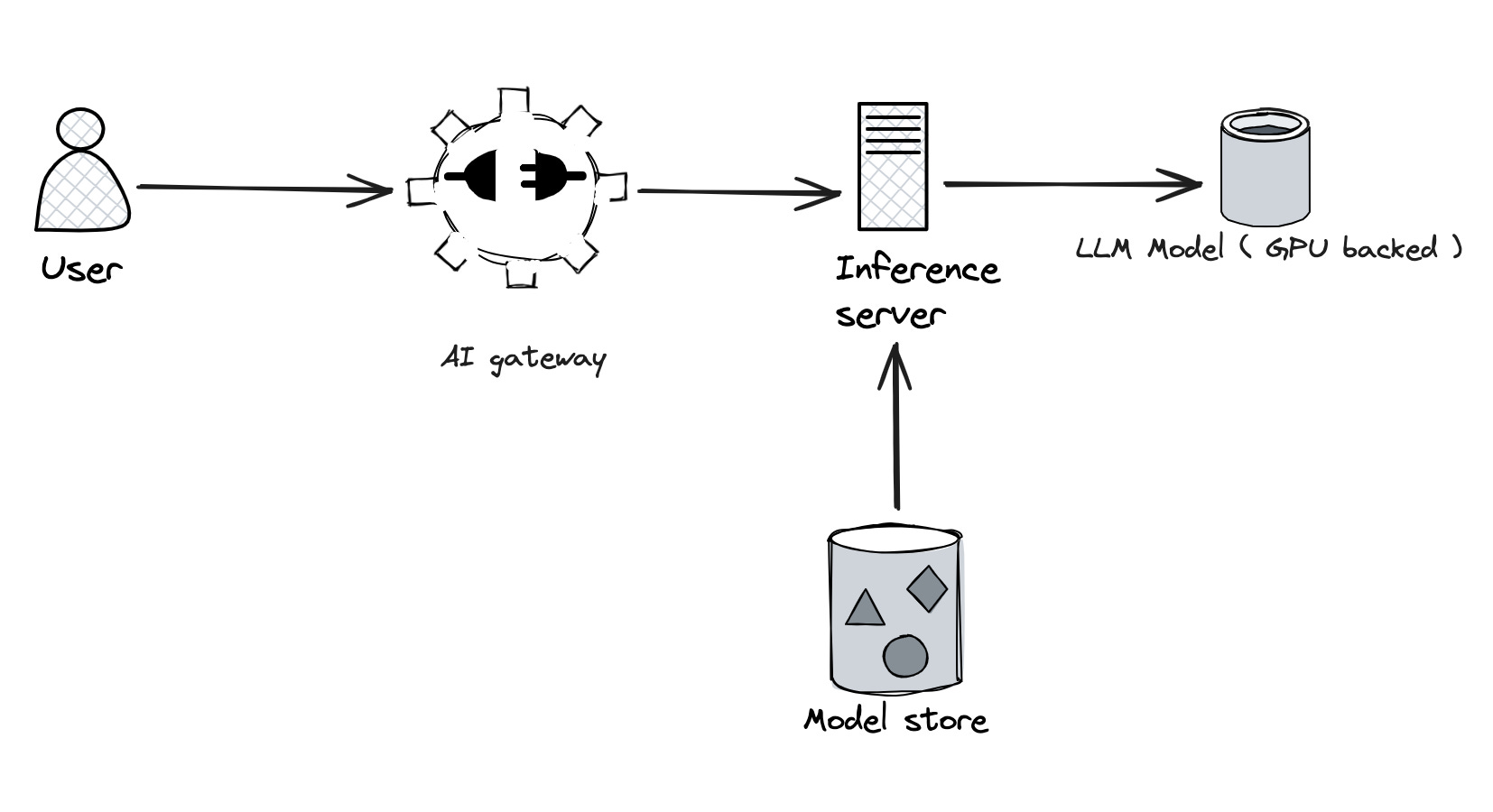

Key Concepts (Buzzwords Decoded)

Kubernetes-Specific Tips
Use GPU node pools with NVIDIA A100/H100 or similar
Enable MIG partitions to run smaller jobs in parallel
Mount model files using CSI or NFS from MinIO/S3
Deploy inference server as a Deployment or Job (depending on latency vs batch)
Expose with Ingress + Service + API Gateway
Use ResourceQuotas to protect GPU resources
Monitor with DCGM Exporter + Prometheus + Grafana Dashboards
Hype vs. Reality

🧭 Should You Care?
Yes — if any of this is true:
Your org wants to self-host LLMs
You need GPU scheduling in Kubernetes
You’re building or scaling model inference APIs
You want to optimize token throughput, latency, and cost
🗺️ Coming Next Week
"Service Mesh: What It Solves, When It Hurts"
Spoiler: You don’t need one until you’re running dozens of services at scale.